From the published article:
In order to investigate the links and potentials of calligraphic performance with sound, a motion capture of this specific practice was carried out.
After an introductory exchange about calligraphic materials, techniques, and processes, we engaged in performing short sequences of calligraphic performance on two sides of a hanging silk-scroll.
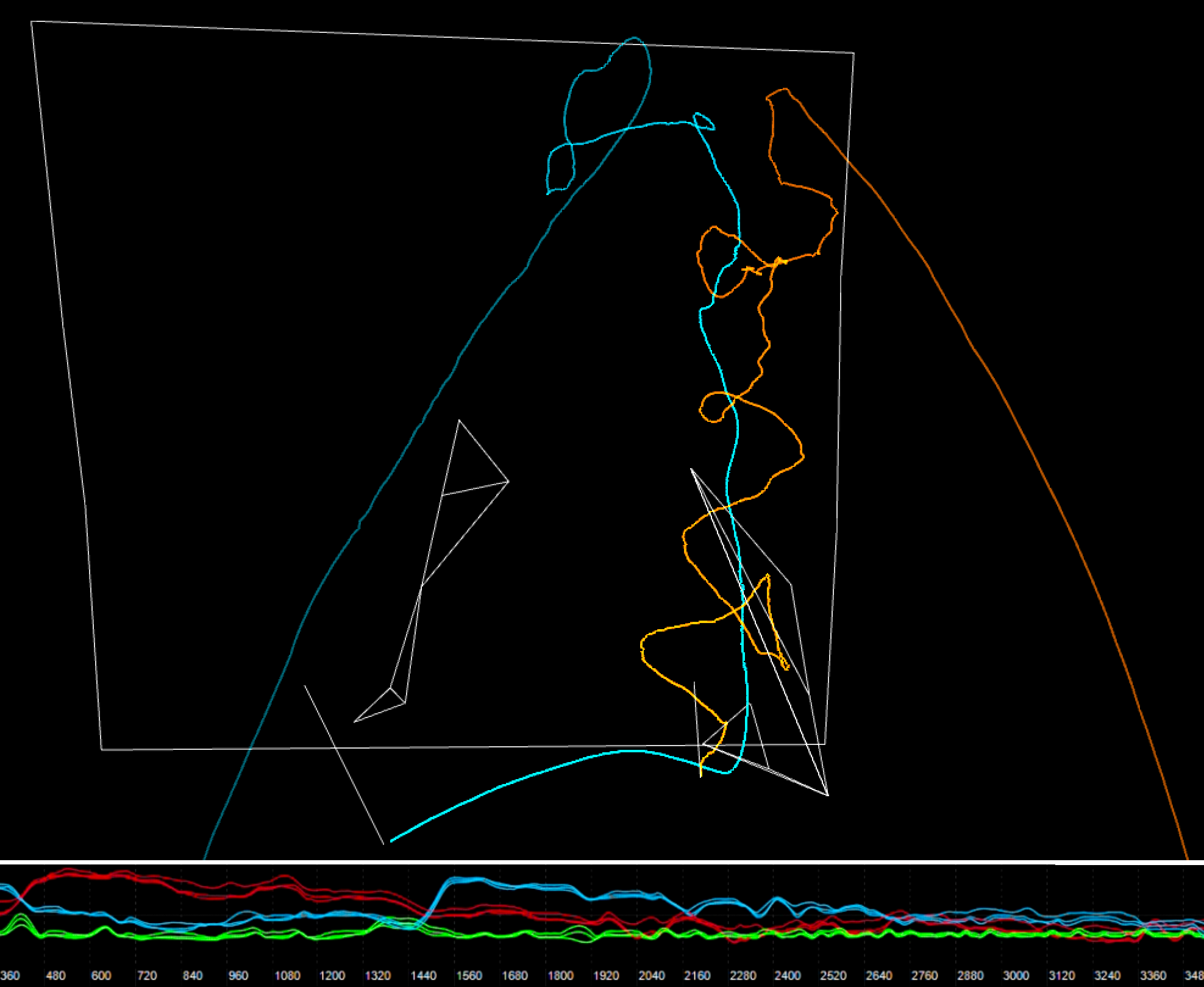
The motion capture system, consisting of 11 cameras running at 100 Hz,was setup in an overlapping dual cube configuration around the centrally placed scroll.
Markers were placed on the performer's right arms and hands, the brushes' tips and ends, as well as the edges of the silk scroll (canvas).
During the capture session, five usable datasets were gathered that represent two characteristic modes of calligraphic performance.
The captured datasets last from around 30 seconds to more than six minutes and are of varying complexity.
In order to provide a baseline, a simplified configuration with a single brush in the conventional calligraphic attitude was recorded: one person draws on a flat canvas with the brushstrokes descending from above.
Three datasets of two-person calligraphy performances were collected, where different dynamics, brushes, and placements of a hanging silk-scroll were carried out.
With water at first and later ink, the successive performances created an increasing density of the visual field and had a notable influence on the stroking actions.
The motion-capture process was complemented by reference-video and audio recordings, which allowed to restitute as much of the actual situation as possible.
In any marker-based capture situation, the constraints of the available equipment and the physical setting make it challenging to obtain marker data without occlusions and drop-outs.
In this case, for example, where an arm-gestures was folded inward towards the scroll and the brush tips pushed into the silk, the important markers on the shoulders got occluded and led to a loss of tracking.
After cleaning and preparing the data-sets the actual work with sound can begin.\footnote{The files are formatted as tab-separated-values with headers corresponding to the Mocap Toolbox (MTB) specification.
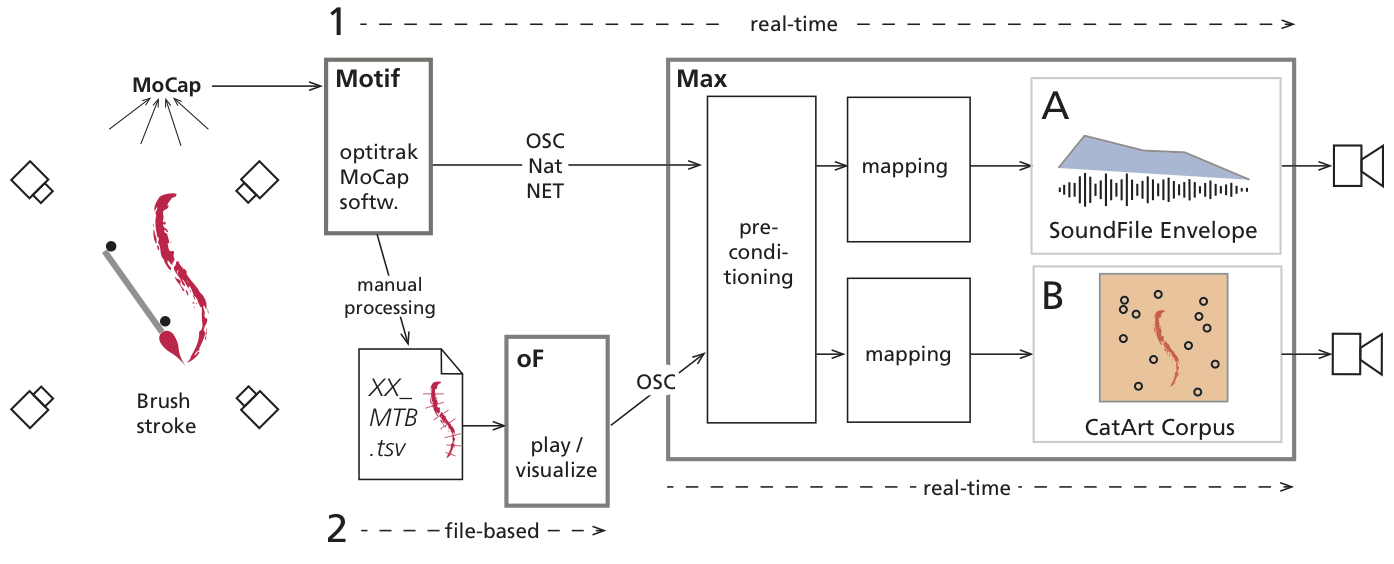
The first step is the elaboration of an initial configuration and connections in software for real-time playback of the captured data coupled with the audio/video recordings.
The main task is to develop a coherent model of stroke-gesture to sound translation.
Technically, the process of generating sound from gesture data uses well established methods: in our case, software written in openFrameworks is used to process and play back the data-sets.
It provides an OSC-stream that carries time-stamps, marker-positions, and their pre-calculated first to third order derivatives.
The sound-engine is made in MaxMSP.
The sound engine implements different synthesis and playback processes, particularly the IRCAM tools for concatenative sound synthesis.
The starting point of the musical process is the decision to augment the brushstrokes with natural sounds instead of synthesised sounds.\footnote{The boundary between synthesis and natural sound-processing is arbitrary, since granulation is also considered a synthesis method, even if it is based on prerecorded materials.}
For the current exploration two types of sound materials were chosen: classical string instruments' bow strokes with extended playing techniques and asian bamboo-flutes with air and breath sounds.
Both materials contain an element of noise or air sound in addition to providing pitched modulated and timbrally rich sounds.
The organic and timbral character of the sounds produces a sonic analogy to the textured ink traces left by the brush on silk.
Therefore, instead of working on a discrete, symbolic level with musical events such as notes, pitches, and rhythms, the organic sounds combined with continuous controls allow for a fluid sound language to emerge.
Based on this premise, two concepts for producing and controlling sound are implemented (see Fig.~\ref{fig:diagram2}).
These processes are:
A) Amplitude-controlled playback of complete sound-phrases of a longer duration, reflecting the dynamics of the stroke gesture.
B) Sound textures that evolve in the dynamic shape of the stroke, accessing a pool of different sounds through granular techniques (CatArt).
The first, onset-based model has the advantage of providing coherent dynamic shapes with a longer sonic phrase, which corresponds to single, long brush actions with an full load of ink.
Here, combining the speed-profile with canvas-proximity calculations allows to shape an existing sonic material with the energy envelope provided by the painting gesture.
As the stroke progresses, so does the sound-material in its naturally recorded form.
The perceptual synchrony occurs through a mimicking relationship between movement energy (speed) and sonic energy (amplitude).
The temporal coherence fosters the fusion of the visual and the sonic gestures into a single multi-modal unit.
The second, corpus-based granular model, provides two aspects of sound processing; onset synchronisation with key-moments in the sound-corpus and timbral evolution across a set of related sound materials.
The evolution of the sound is mapped homogeneously to the physical space of the brush-stroke: the positional data of the motion-captured brush is used spatially navigating within a map of the sound corpus .
Concretely, this means that the 2D-position of the brush on the canvas is mapped to a 2D-representation of the corpus' parameter space.
Thanks to this, the speed-profile (first derivative of position changes) is complemented by the acceleration profile, which alters the grain-size of the synthesis algorithm and renders the sonification more differentiated.
This technique enables the assignment of specific timbral parameters to specific gestural characteristics of the brush-stroke.
Tests with further calculable movement descriptors, such as the Laban Effort descriptors `weight-effort' or `flow-effort', reveal that higher order interpretations of brush-point data yield no significant increase in perceptual coherence.